|
|
 |
 |
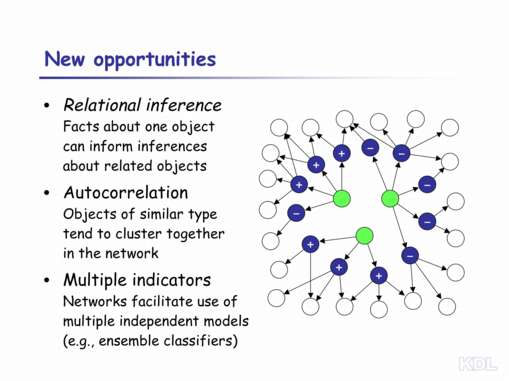
| I've spoken a great deal about the difficulties inherent in analyzing relational data, but I should also mention the opportunities.
Relational data allow relational inference, so that inferences made about one object (e.g., a particular bank account) can inform inferences about other objects (e.g., other accounts owned by the same person). This opportunity may be easier to understand in terms of relational autocorrelation. In the fragment of relational data above, we have one object represented by blue nodes whose label (+ or –) is autocorrelated with respect to paths through another type of object represented by green nodes. That is, nearly all blue nodes connected to a given green node have the same label (either + or –). The most common value can vary, but the values for a given green node are almost always identical. For example, bank accounts (blue nodes) held by a single individual (green nodes) could either tend to be all involved in money laundering (+) or not (–). Knowledge about autocorrelation can be exploited to improve classification of individual nodes. In addition to relational inference and autocorrelation, relational data can enable data mining methods to construct multiple independent models, each of which exploits a different set of relations. Using these models together, commonly called an ensemble classifier, can greatly improve the accuracy of the resulting inferences. |