|
|
 |
 |
| Data mining for counter-terrorism requires a set of new capabilities that are not found in current commercial tools.
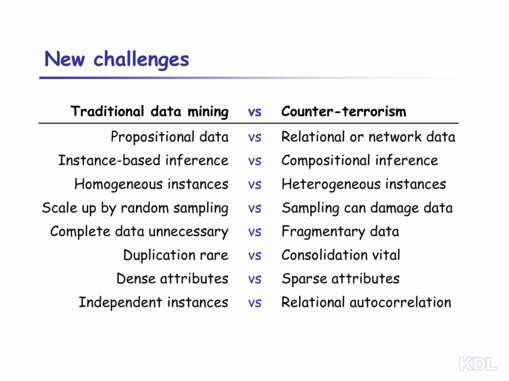
Some of these new capabilities concern how to treat individual data instances. Traditional data mining systems assume that data sets contain unrelated instances (also referred to as propositional data), while many types of counter-terrorism analysis uses relational or network data. Traditional data mining makes inferences about instances while counter-terrorism analysis often make inferences about compositions or sets of instances. Traditional data mining assumes that data instances are homogeneous (e.g., every data record represents a medical patient), while counter-terrorism analysis often addresses sets of heterogeneous instances (e.g., people, places, and things). Other changes are needed in how entire data sets are handled. Random samples of propositional data can be used to construct valid statistical models, but simple random sampling can damage relational data by removing connections between parts of the network. With propositional data, inferring a valid model is possible even if all data (e.g., all Alzheimer's patients) are not available; in relational data, fragmentary data (e.g., some missing business associations or bank transactions) can cause errors in naive methods for data mining. Most propositional data sets are drawn from a single source, so it is rare to have duplicate records for a single instance (e.g., a patient); relational data are often drawn from multiple sources, so it is vital to consolidate multiple records of the same real-world entity or relation. Finally, data instances in propositional data sets are assumed to be statistically independent. In contrast, relational data sets often exhibit relational autocorrelation, where instances of a given type tend to cluster together. For example, the financial transactions involved in money laundering are not uniformly distributed across all accounts, banks, and individuals. Instead, they tend to be carried out by a small number of accounts, banks, and individuals. Not adjusting for autocorrelation can lead to important errors in learned models. |