|
|
 |
 |
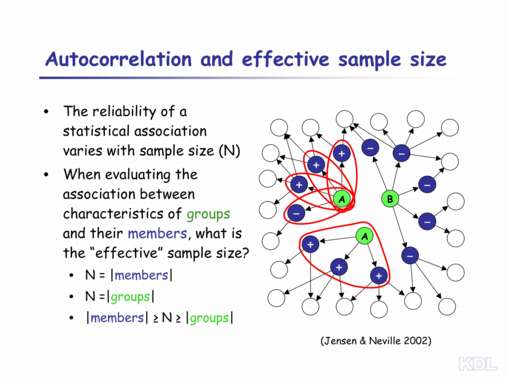
| Let me give you another example of the complexity of applying data mining techniques, again drawn from work in my own laboratory. As I'm sure you know, the reliability of any observed statistical association varies with sample size (N). The larger the sample size, the more certain you can be that a given observed association is not merely due to chance. In relational data, however, it can be difficult to estimate sample size. For example, consider the data shown on the right. Suppose we were trying to evaluate the association between some characteristic of green nodes (A/B) and a characteristic of blue nodes (+/–). What certainty should we assign to the rule: A implies +, and B implies – One measure of N would be the number of pairs of blue and green nodes. This is equivalent to the number of blue nodes (in this case, twelve). This would be appropriate if we assume that the labels on each blue node are independent. From examination, this appears unlikely, given the autocorrelation evident among the blue node labels. Another measure would be the number of green nodes (three). This would be appropriate if we assume that the labels on the blue nodes are completely dependent (i.e., all blue nodes associated with a given green node receive a single label). This appears closer to the truth, though still inaccurate. In actuality, a value somewhere in between is most appropriate. A student of mine, Jen Neville, and I discuss estimating this "effective sample size" in more detail in a paper we published last year. We show how this type of estimation problem can cause data mining algorithms to construct poor statistical models. It can cause algorithms to prefer models with the least statistical support from the data, rather than selecting models with the most support. We are working out ways of adjusting for this, and other, sources of bias that arise in relational data. |