|
|
 |
 |
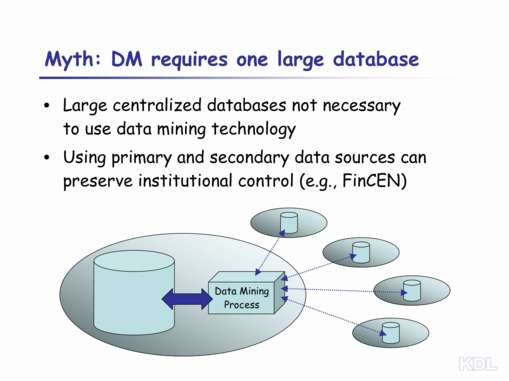
| One of the persistent myths of data gathering is that all relevant data must be stored in a single, massive database. Such a massive database raises both technical and policy concerns. There are a variety of technical barriers to constructing, searching, and updating such a database. The policy concerns include the ability to keep such a database secure from intruders and ensuring that those individuals with legitimate access to the data do not misuse their authority. Data mining techniques do not require such a massive database. Provided that certain (very low) size thresholds are exceeded to provide statistical validity, data mining techniques can be applied to databases of a wide variety of sizes. Rather than assembling all relevant data in a single, massive database, a more reasonable approach may be to view data as consisting of primary and secondary data sets. For example, FinCEN viewed the currency transaction reports (currency transactions over $10,000) as primary data. The agency controlled the data, and they could search and correlate these records at will. When analysis of primary data indicated a high probability that a particular individual or business was involved in money laundering, then FinCEN analysts sought access to other, secondary data sets that were controlled by other organizations (e.g., other Federal agencies, or state or local law enforcement). This approach keeps institutional control of databases distributed, providing a bulwark against both outside intruders and widespread institutional misuse. |