|
|
 |
 |
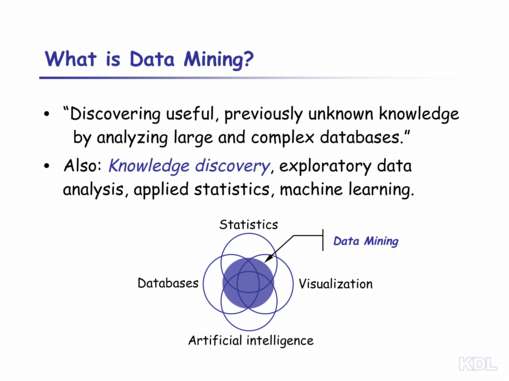
| Data mining algorithms discover useful, previously unknown knowledge by analyzing large databases. In a broad sense, these techniques are not new. Previous techniques have gone by other names, including "exploratory data analysis", "applied statistics", and "machine learning".
The name commonly used by many researchers in the field is "knowledge discovery". In many ways, "knowledge discovery" is a far better name than "data mining". These technologies do not "mine for data"; they "mine for knowledge" — they look through data to find knowledge. Calling this process "data mining" is like calling gold mining "rock mining", because we look through rock to find gold. Still, the name "data mining" is the one most commonly used by news stories about the technology. It's stuck, so I'll use it here. While we're discussing terminology, I should note that it is sometimes excessive to use the term "knowledge" to describe the statistical models constructed by data mining algorithms. Some of these models are very difficult to understand technically, and others are too large and complex to comprehend easily. Still, I will use the term "knowledge". Again, the term has stuck, so I will use it here. What differentiates current research in data mining from past research in applied statistics and machine learning is that the field fuses work in databases, statistics, artificial intelligence, and visualization. Databases provides expertise on efficient data storage and access, statistics provides expertise in making valid inferences from data, artificial intelligence provides expertise in representing knowledge and in efficient search of large spaces of possible models, and visualization provides valuable tools to help human analysts examine large amounts of complex data. Current research in data mining draws on all of these fields. |